之前我們已經討論過 Indexing pipeline 是怎麼把知識存進去,現在就要來看 Generation pipeline 如何把知識「取出來用」。
這邊可以先回顧一下Day 2|RAG 的基本架構,今天換個角度,把其中 Generation pipeline 拉出來單獨走一遍,看看每一步會發生什麼事。
小小的幫大家畫一下關係圖,這樣才不會覺得很混亂,關係圖如下:
RAG
├── Indexing pipeline (建資料庫)
└── Generation pipeline (用資料庫回答)
好回到今天的重點 Generation pipeline ,我們先看這張圖,其實跟第二天那張圖是一樣的,只是為了方便大家觀看,這邊找了張比較易懂的圖片: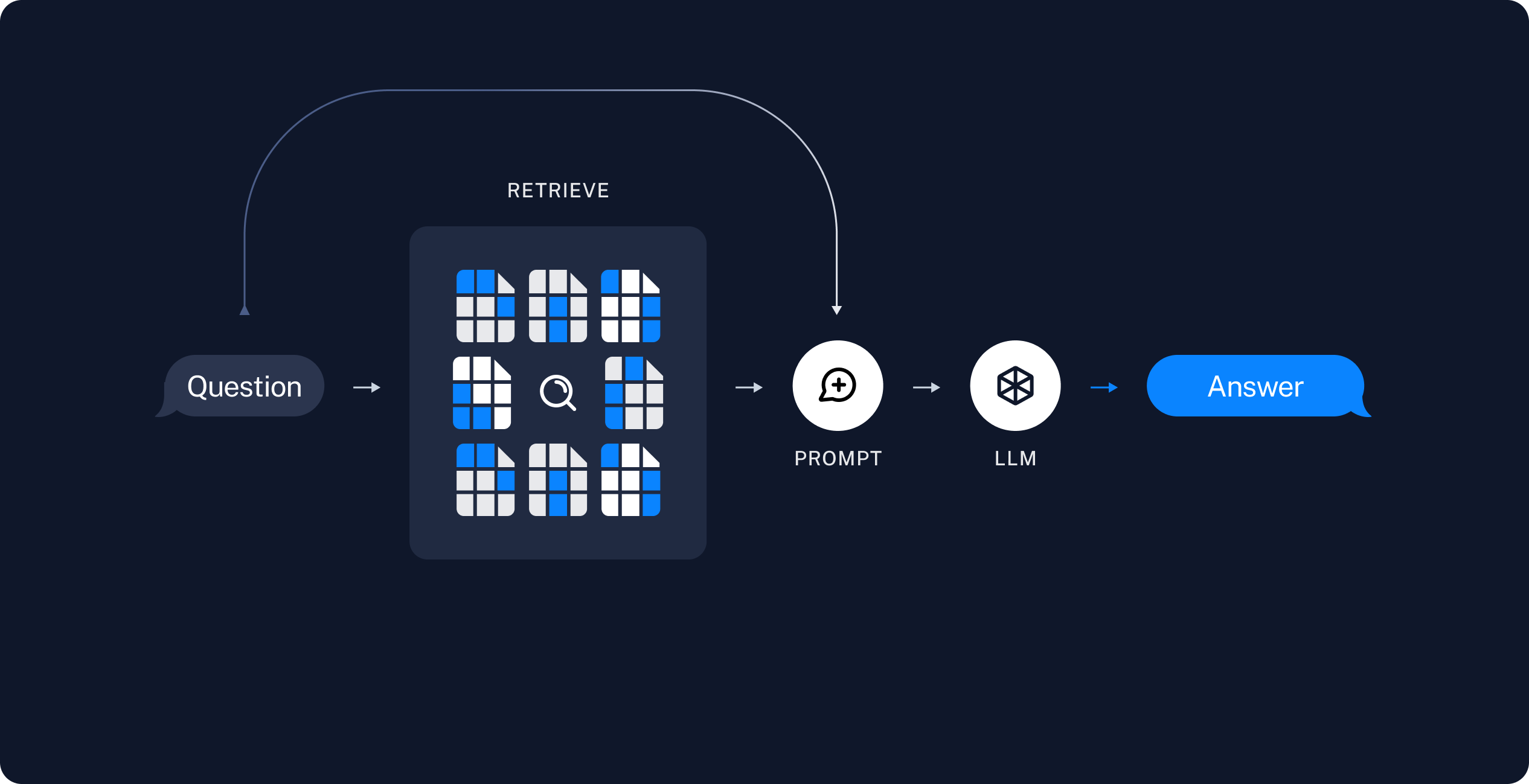
來源:Build a Retrieval Augmented Generation (RAG) App: Part 1
這邊的流程是:
我們這邊其實要專注的是 2-5 步驟的部分,也是我們接下來要分享的部分。
這邊說明一下 RAG = Retrieval + Generation。Generation pipeline 是 RAG 的「用知識回答」這一半,不是 RAG 的超集合,也不是把 RAG 再包一次。
這一步會從**向量資料庫(Vector DB)**裡找出與 Query 最相關的 k 個片段(chunks)。
顧名思義就是去找資料,跟上面說的一樣就是從之前 Indexing pipeline 中建立的資料庫去找最相關的文件片段。
這個過程通常依賴 Embedding 向量 來衡量相似度(可以回顧 Day 4|Embedding 是什麼?——如何把文字變成數字空間),但檢索的方法並不只有一種,例如:TF-IDF、BM25......,我們之後會介紹這幾種檢索方式。
檢索器的重要性非常高,因為 你餵給 LLM 的內容準不準,會直接影響到它的回覆品質。如果找錯段落,再強大的模型也可能「答非所問」。
把 Query 與檢索到的片段,組裝成 結構化的 prompt。常見技巧:
接著,大語言模型會讀取這個 Prompt,並輸出答案。這裡牽涉到的考量包含:
模型大小:大模型更聰明,但資源需求高;小模型較快,適合邊緣裝置。
模型來源:專有模型(OpenAI、Anthropic) vs. 開源模型(LLaMA、Mistral)。
是否微調:基礎模型知識廣,但微調模型在特定領域(如醫療、法律)更精準。
不是「Generation pipeline 裡又包一個 RAG」,而是 在生成這一步,模型依據前一步 Augmentation 的外部知識來作答,這邊必須再次解釋清楚一下,避免大家混亂
希望今天的概念有讓大家更明白整個 RAG 的運作,後面幾天再把 檢索方式 跟 prompt engineering 再說明詳細點。

